内田研究室の研究テーマ
(4)半導体レーザカオスを用いた強化学習
1.多腕バンディット問題とは?
強化学習は教師データを必要としない学習方法であり、環境から報酬を得ることを繰り返すことにより学習を行います。強化学習の問題例の一つとして、多腕バンディット問題が知られています[1]。この問題では、未知の当たり確率を持つ複数台のスロットマシンを仮定します。プレーヤーはスロットマシンから得られる報酬(当たり)を学習することで総報酬を最大化します。この問題は株取引[2]や無線通信の効率化[3]に応用することができます。
多腕バンディット問題を解くための手順として「探索」と「知識利用」の2つが必要となります。「探索」とは、スロットマシンの当たり確率を推定するためにスロットマシンを選択することです。一方で「知識利用」とは、報酬の最大化をするために当たり確率が最も高いスロットマシンを選択することです。しかしながら「探索」と「知識利用」はどちらに偏っても報酬を最大化することができません。そのために「探索」と「知識利用」のバランスが重要となります。
多腕バンディット問題を解くアルゴリズムとして、綱引き理論が提唱されています[4]。綱引き理論は図1のように、報酬に応じて綱引きのように綱を引っ張り合い、綱の位置から各スロットマシンを選択する頻度を変える方法です
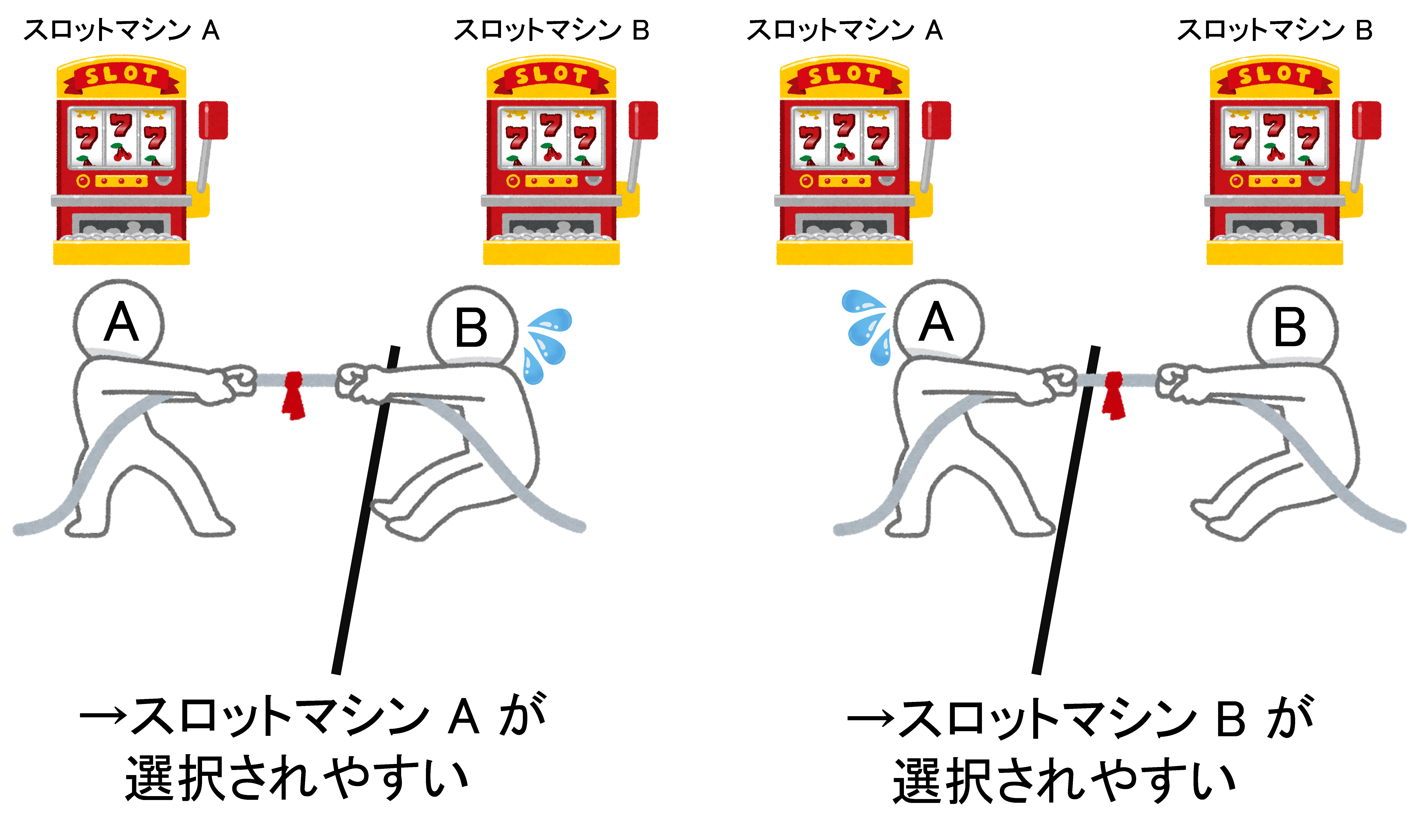 図1. 綱引き理論[4]の概念図
図1. 綱引き理論[4]の概念図
2.半導体レーザカオスと綱引き理論
半導体レーザカオスを用いた綱引き理論による解法[5]では、図2に示すように、半導体レーザのカオス的出力の複雑かつ高速な時間波形に対して、可動なしきい値を設定します。ある時刻における時間波形の値がしきい値よりも大きい場合にはスロットマシンAを選択し、小さい場合にはスロットマシンBを選択します。また、スロットマシンAを選択して「当たり」が出た場合、スロットマシンAを次に選択しやすくなるように、しきい値を下に移動させます。反対に、スロットマシンAを選択して「はずれ」が出た場合、スロットマシンAを次に選択しにくくなるように、しきい値を上に移動させます。
以上の方式を繰り返すことで、半導体レーザカオスを用いた高速な強化学習が実現できます。
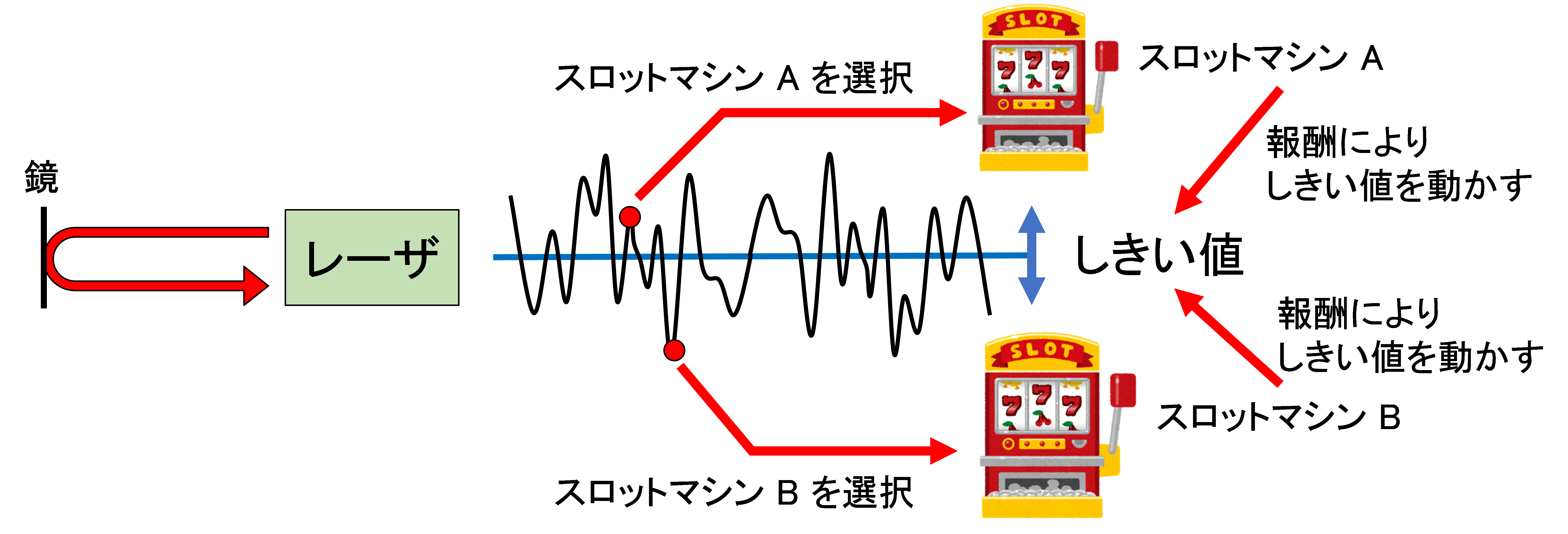 図2. 多腕バンディット問題を解くための半導体レーザカオスを用いた実装方法[5]
図2. 多腕バンディット問題を解くための半導体レーザカオスを用いた実装方法[5]